7 Fitting a model to data
7.1 Introducing likelihood functions
In Gadget, a likelihood function is specified by supplying likelihood components within the likelihood file, which is referred to by the main file. Individual likelihood component scores are summed together after being multiplied by weights to form a total likelihood score, and each likelihood score is defined by the type of likelihood component specified. Component types define both the kind of data and likelihood function being calculated for that component. Although we refer to ‘likelihood scores’ throughout this description, it should be kept in mind that these are more accurately sums of log likelihoods, so that the objective function used for model fitting attempts to minimize the total likelihood score.
7.2 Incorporating data (Ling case study cont.)
In introducing likelihood components, we will first go through those used within the ling example in detail, but only mention the other types as they follow similar patterns of implementation. To use Rgadget to set up likelihood files, the first consideration that should be made is what data are available that would be useful for creating a likelihood component. These have been provided for you here: in the ‘data_provided’ folder, you will find catch data (as introduced with the fleets), as well as survey indices, catch distribution, and ‘stock’ distribution data. Catch distributions include numbers at length as well as numbers at age and length by fleet. These therefore include both biological samples in fishery data as well as survey data. Each length- or age-bin has been defined as having the lower bound only inclusive, except that the lower bound of the smallest bin and the upper bound of the largest bin are open-ended to include all values lower or higher, respectively. These numbers are then used within Gadget to form proportions among defined bins, which are compared to the same proportions among the same bins simulated in the model. Stock distribution data are numbers within each stock, which for ling is immature or mature, but could for example be gender-specific stocks. Stock distribution numbers are similarly used to form proportions within Gadget.
As we saw when incorporating catch data into fleet files (day 2), certain attributes need to be present in order for the proper and internally consistent Gadget aggregation files to be created alongside these data files. For catch and stock distribution data, these include area, length, and age aggregations. Even when there is only a single bin, these aggregations need to be specified. For example a single area and a single age group is needed for length distributions, in addition to the length bins. Note that bins need not be evenly distributed across the total length range; instead they are highly flexible and can be specified as any grouping. Therefore the user should be careful to ensure that the definitions make sense and that bins do not overlap. In our example below, we show how to add those necessary attributes, although in reality to do this we also use another R package named ‘mfdb’ that is aimed at database management and data extraction [more on this in day 5].
library(tidyverse)
library(Rgadget)
#assuming you are beginning in a fresh session; this information should be in an
#initialization script
base_dir <- 'ling_model'
vers <- c('01-base')
gd <- normalizePath(gadget.variant.dir(sprintf(paste0("%s/",vers),base_dir)))
ling.imm <- gadgetstock('lingimm',gd)
ling.mat <- gadgetstock('lingmat',gd)
area_file <- read.gadget.file(gd, 'Modelfiles/area')
minage <- ling.imm[[1]]$minage
maxage <- ling.mat[[1]]$maxage
maxlength <- ling.mat[[1]]$maxlength
minlength <- ling.imm[[1]]$minlength
dl <- ling.imm[[1]]$dl
create_intervals <- function (prefix, vect) {
x<-
structure(vect[1:(length(vect)-1)], names = paste0(prefix, vect[1:(length(vect)-1)])) %>%
as.list(.) %>%
purrr::map(~structure(seq(.,vect[-1][which(vect[1:(length(vect)-1)]==.)],1)[-length(seq(.,vect[-1][which(vect[1:(length(vect)-1)]==.)],1))],
min = .,
max = vect[-1][which(vect[1:(length(vect)-1)]==.)]))
x[[length(x)]] <- c(x[[length(x)]], attributes(x[[length(x)]])$max) %>%
structure(.,
min = min(.),
max = max(.))
return(x)
}
#just to see what this function does:
create_intervals('len',seq(minlength, maxlength, dl)) %>% .[1:3]## $len20
## [1] 20 21 22 23
## attr(,"min")
## [1] 20
## attr(,"max")
## [1] 24
##
## $len24
## [1] 24 25 26 27
## attr(,"min")
## [1] 24
## attr(,"max")
## [1] 28
##
## $len28
## [1] 28 29 30 31
## attr(,"min")
## [1] 28
## attr(,"max")
## [1] 32#catch distribution data available:
#length distributions do not regard age bins
ldist.surv <- structure(read_csv('data_provided/ldist_sur.csv'),
area = list(area_file[[1]]$areas) %>% set_names(.),
length = create_intervals('len',seq(minlength, maxlength, dl)),
age = create_intervals('all',seq(minage, maxage, maxage-minage))
)
ldist.lln <- structure(read_csv('data_provided/ldist_lln.csv'),
area = list(area_file[[1]]$areas) %>% set_names(.),
length = create_intervals('len',seq(minlength, maxlength, dl)),
age = create_intervals('all',seq(minage, maxage, maxage-minage))
)
ldist.bmt <- structure(read_csv('data_provided/ldist_bmt.csv'),
area = list(area_file[[1]]$areas) %>% set_names(.),
length = create_intervals('len',seq(minlength, maxlength, dl)),
age = create_intervals('all',seq(minage, maxage, maxage-minage))
)
ldist.gil <- structure(read_csv('data_provided/ldist_gil.csv'),
area = list(area_file[[1]]$areas) %>% set_names(.),
length = create_intervals('len',seq(minlength, maxlength, dl)),
age = create_intervals('all',seq(minage, maxage, maxage-minage))
)
attributes(ldist.surv) %>%
purrr::map(head)## $names
## [1] "year" "step" "area" "age" "length" "number"
##
## $class
## [1] "spec_tbl_df" "tbl_df" "tbl" "data.frame"
##
## $row.names
## [1] 1 2 3 4 5 6
##
## $spec
## $spec$cols
## $spec$cols$year
## <collector_double>
##
## $spec$cols$step
## <collector_double>
##
## $spec$cols$area
## <collector_double>
##
## $spec$cols$age
## <collector_character>
##
## $spec$cols$length
## <collector_character>
##
## $spec$cols$number
## <collector_double>
##
##
## $spec$default
## <collector_guess>
##
## $spec$skip
## [1] 1
##
##
## $area
## $area$`1`
## [1] 1
##
##
## $length
## $length$len20
## [1] 20 21 22 23
## attr(,"min")
## [1] 20
## attr(,"max")
## [1] 24
##
## $length$len24
## [1] 24 25 26 27
## attr(,"min")
## [1] 24
## attr(,"max")
## [1] 28
##
## $length$len28
## [1] 28 29 30 31
## attr(,"min")
## [1] 28
## attr(,"max")
## [1] 32
##
## $length$len32
## [1] 32 33 34 35
## attr(,"min")
## [1] 32
## attr(,"max")
## [1] 36
##
## $length$len36
## [1] 36 37 38 39
## attr(,"min")
## [1] 36
## attr(,"max")
## [1] 40
##
## $length$len40
## [1] 40 41 42 43
## attr(,"min")
## [1] 40
## attr(,"max")
## [1] 44
##
##
## $age
## $age$all3
## [1] 3 4 5 6 7 8 9 10 11 12 13 14 15
## attr(,"min")
## [1] 3
## attr(,"max")
## [1] 15#age bins needed for age-length distributions
aldist.surv <- structure(read_csv('data_provided/aldist_sur.csv'),
area = list(area_file[[1]]$areas) %>% set_names(.),
length = create_intervals('len',seq(minlength, maxlength, dl)),
age = create_intervals('age',c(minage:11, maxage))
)
aldist.lln <- structure(read_csv('data_provided/aldist_lln.csv'),
area = list(area_file[[1]]$areas) %>% set_names(.),
length = create_intervals('len',seq(minlength, maxlength, dl)),
age = create_intervals('age',c(minage:11, maxage))
)
aldist.bmt <- structure(read_csv('data_provided/aldist_bmt.csv'),
area = list(area_file[[1]]$areas) %>% set_names(.),
length = create_intervals('len',seq(minlength, maxlength, dl)),
age = create_intervals('age',c(minage:11, maxage))
)
aldist.gil <- structure(read_csv('data_provided/aldist_gil.csv'),
area = list(area_file[[1]]$areas) %>% set_names(.),
length = create_intervals('len',seq(minlength, maxlength, dl)),
age = create_intervals('age',c(minage:11, maxage))
)
attributes(aldist.surv)$age %>% head(3)## $age3
## [1] 3
## attr(,"min")
## [1] 3
## attr(,"max")
## [1] 4
##
## $age4
## [1] 4
## attr(,"min")
## [1] 4
## attr(,"max")
## [1] 5
##
## $age5
## [1] 5
## attr(,"min")
## [1] 5
## attr(,"max")
## [1] 6#stock distribution data available:
matp.surv <- structure(read_csv('data_provided/matp_sur.csv'),
area = list(area_file[[1]]$areas) %>% set_names(.),
length = create_intervals('len',seq(minlength, maxlength, dl*2)),
age = list(mat_ages = ling.mat[[1]]$minage:ling.mat[[1]]$maxage)
)
#attributes(matp.surv)For ling, length-based indices were used by choosing 7 ‘slices’ of abundance indices across the
length range of ling observed. Index bounds are defined as above, generally inclusive of the
lower bound only, but open-ended for the smallest and largest bins. It is important to note
that only area and length attributes are included as attributes on these data frames, rather than
age, as in the distributional components. The length attribute allows gadget_update to recognize
these data as length-based indices, rather than age-based or acoustic indices, for example. It is
also important to keep in mind
here that each slice will have its own estimated catchability per survey (single data frame below)
and area combination (multiple areas may be within a data frame).
#survey index data available:
slices <-
list('len20' = c(20,52), 'len52' = c(52,60), 'len60' = c(60,72),
'len72' = c(72,80), 'len80' = c(80,92), 'len92' = c(92,100),
'len100' = c(100,160) )
# just to illustrate slices:
ldist.surv %>%
mutate(length = substring(length, 4) %>% as.numeric) %>%
filter(year %in% c(2000,2005,2010,2015)) %>%
group_by(year,length) %>%
summarise(n = sum(number)) %>%
ggplot(aes(x = length, y = n)) + geom_line() +
geom_vline(aes(xintercept = length),
lty = 2, col = 'orange',
data = slices %>%
bind_rows() %>%
t() %>% .[-1,1] %>%
tibble(length = .)) +
facet_wrap(~year)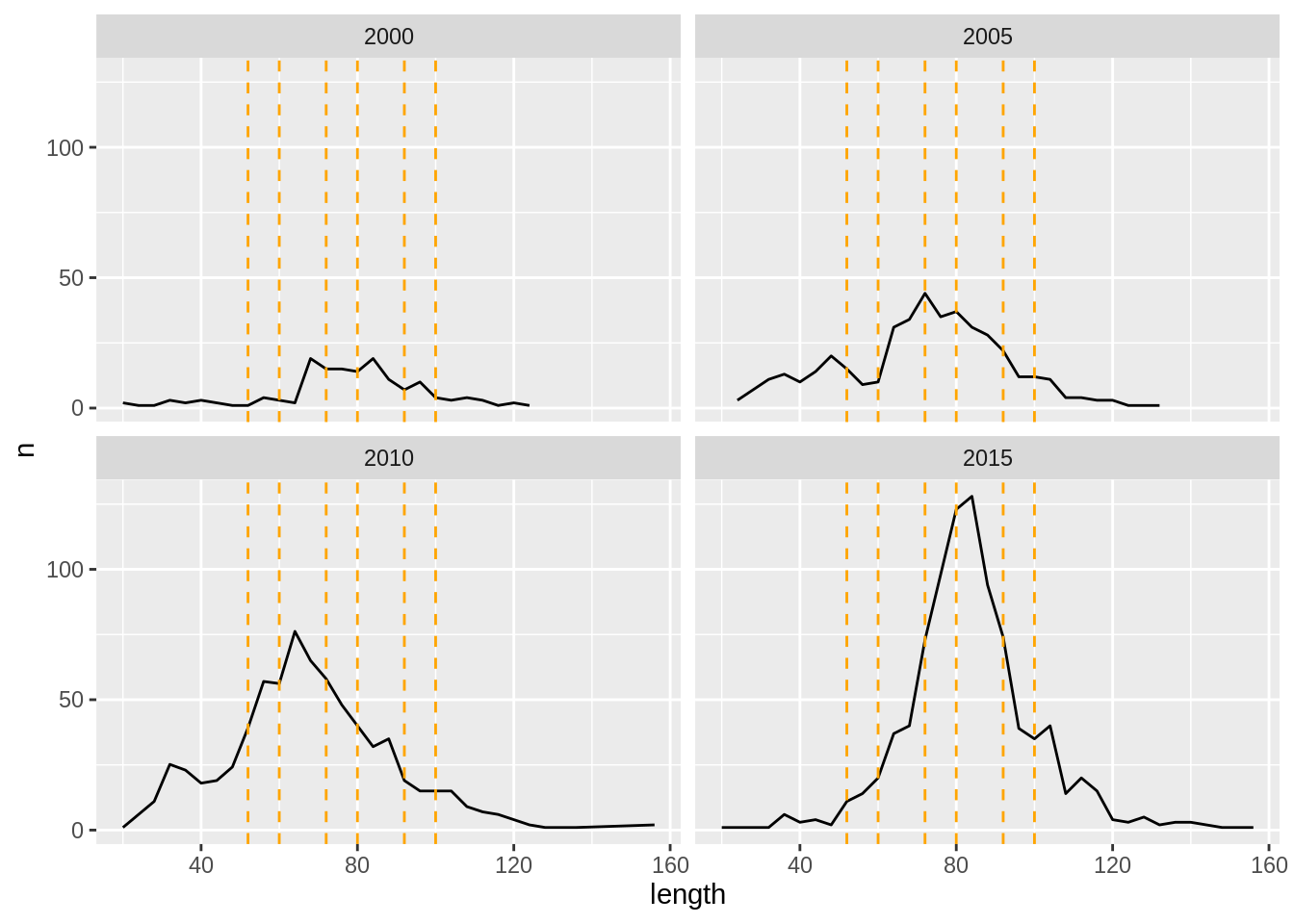
# set up aggregation info for length-based survey indices
SI1 <- structure(read_csv('data_provided/SI1.csv'),
area = list(area_file[[1]]$areas) %>% set_names(.),
length = create_intervals('len', slices[[1]]))
SI2 <- structure(read_csv('data_provided/SI2.csv'),
area = list(area_file[[1]]$areas) %>% set_names(.),
length = create_intervals('len', slices[[2]]))
SI3 <- structure(read_csv('data_provided/SI3.csv'),
area = list(area_file[[1]]$areas) %>% set_names(.),
length = create_intervals('len', slices[[3]]))
SI4 <- structure(read_csv('data_provided/SI4.csv'),
area = list(area_file[[1]]$areas) %>% set_names(.),
length = create_intervals('len', slices[[4]]))
SI5 <- structure(read_csv('data_provided/SI5.csv'),
area = list(area_file[[1]]$areas) %>% set_names(.),
length = create_intervals('len', slices[[5]]))
SI6 <- structure(read_csv('data_provided/SI6.csv'),
area = list(area_file[[1]]$areas) %>% set_names(.),
length = create_intervals('len', slices[[6]]))
SI7 <- structure(read_csv('data_provided/SI7.csv'),
area = list(area_file[[1]]$areas) %>% set_names(.),
length = create_intervals('len', slices[[7]]))7.2.1 Exercise
- Change the aggregation levels of the age-length distribution data so that data are compared to model results within the bins 3 - 6, 7, 8, 9, 10 - 11, and 12 - 15.
7.3 Setting up likelihood components
Using Rgadget, writing the files that specify the likelihood componenets is straightforward.
When calling gadgetlikelihood and then writing it with write.gadget.file, a likelihood file
is created within R and written to disc. The likelihood file contains a list of likelihood
component specifications, and within each component is where the likelihood function, data, and
weighting of the likelihood component is specified.
Here we start with the distributional components. In all cases, each component receives a distinct
name (to be referenced later so keep them short and distinct), weights (1 to yield equal weights
for now), data as imported above, and the fleet names and stock names to which these data apply.
As a default, Rgadget specifies a sum of squares function to calculate the likelihood score
(sumofsquares), although a variety of other functions are possible, including one for stratified
sum of squares (stratified), multinomial function (multinomial), pearson function (pearson),
gamma function (gamma), log function (log), multivariate normal function (mvn) or a
multivariate logistic function (mvlogistic). Many of these functions have been tailored for
specific data situations (e.g., including tagging or predation data into a likelihood component).
More on these functions can be read in the Gadget User Guide. To change the default setting to
the stratified sum of squares, for example, one would include an additional argument function = 'stratified', to the gadget_update call.
lik <-
gadgetlikelihood('likelihood',gd,missingOkay = TRUE) %>%
gadget_update("catchdistribution",
name = "ldist.surv",
weight = 1,
data = ldist.surv,
fleetnames = c("surv"),
stocknames = c("lingimm","lingmat")) %>%
gadget_update("catchdistribution",
name = "aldist.surv",
weight = 1,
data = aldist.surv,
fleetnames = c("surv"),
stocknames = c("lingimm","lingmat")) %>%
gadget_update("catchdistribution",
name = "ldist.lln",
weight = 1,
data = ldist.lln,
fleetnames = c("lln"),
stocknames = c("lingimm","lingmat")) %>%
gadget_update("catchdistribution",
name = "aldist.lln",
weight = 1,
data = aldist.lln,
fleetnames = c("lln"),
stocknames = c("lingimm","lingmat")) %>%
gadget_update("catchdistribution",
name = "ldist.gil",
weight = 1,
data = ldist.gil,
fleetnames = c("gil"),
stocknames = c("lingimm","lingmat")) %>%
gadget_update("catchdistribution",
name = "aldist.gil",
weight = 1,
data = aldist.gil,
fleetnames = c("gil"),
stocknames = c("lingimm","lingmat")) %>%
gadget_update("catchdistribution",
name = "ldist.bmt",
weight = 1,
data = ldist.bmt,
fleetnames = c("bmt"),
stocknames = c("lingimm","lingmat")) %>%
gadget_update("catchdistribution",
name = "aldist.bmt",
weight = 1,
data = aldist.bmt,
fleetnames = c("bmt"),
stocknames = c("lingimm","lingmat")) %>%
gadget_update("stockdistribution",
name = "matp.surv",
weight = 1,
data = matp.surv,
fleetnames = c("surv"),
stocknames =c("lingimm","lingmat"))
lik## ; Generated by Rgadget 0.5
## ;
## [component]
## name ldist.surv
## weight 1
## type catchdistribution
## datafile Data/catchdistribution.ldist.surv.sumofsquares
## function sumofsquares
## aggregationlevel 0
## overconsumption 0
## epsilon 10
## areaaggfile Aggfiles/catchdistribution.ldist.surv.area.agg
## ageaggfile Aggfiles/catchdistribution.ldist.surv.age.agg
## lenaggfile Aggfiles/catchdistribution.ldist.surv.len.agg
## fleetnames surv
## stocknames lingimm lingmat
## ;
## [component]
## name aldist.surv
## weight 1
## type catchdistribution
## datafile Data/catchdistribution.aldist.surv.sumofsquares
## function sumofsquares
## aggregationlevel 0
## overconsumption 0
## epsilon 10
## areaaggfile Aggfiles/catchdistribution.aldist.surv.area.agg
## ageaggfile Aggfiles/catchdistribution.aldist.surv.age.agg
## lenaggfile Aggfiles/catchdistribution.aldist.surv.len.agg
## fleetnames surv
## stocknames lingimm lingmat
## ;
## [component]
## name ldist.lln
## weight 1
## type catchdistribution
## datafile Data/catchdistribution.ldist.lln.sumofsquares
## function sumofsquares
## aggregationlevel 0
## overconsumption 0
## epsilon 10
## areaaggfile Aggfiles/catchdistribution.ldist.lln.area.agg
## ageaggfile Aggfiles/catchdistribution.ldist.lln.age.agg
## lenaggfile Aggfiles/catchdistribution.ldist.lln.len.agg
## fleetnames lln
## stocknames lingimm lingmat
## ;
## [component]
## name aldist.lln
## weight 1
## type catchdistribution
## datafile Data/catchdistribution.aldist.lln.sumofsquares
## function sumofsquares
## aggregationlevel 0
## overconsumption 0
## epsilon 10
## areaaggfile Aggfiles/catchdistribution.aldist.lln.area.agg
## ageaggfile Aggfiles/catchdistribution.aldist.lln.age.agg
## lenaggfile Aggfiles/catchdistribution.aldist.lln.len.agg
## fleetnames lln
## stocknames lingimm lingmat
## ;
## [component]
## name ldist.gil
## weight 1
## type catchdistribution
## datafile Data/catchdistribution.ldist.gil.sumofsquares
## function sumofsquares
## aggregationlevel 0
## overconsumption 0
## epsilon 10
## areaaggfile Aggfiles/catchdistribution.ldist.gil.area.agg
## ageaggfile Aggfiles/catchdistribution.ldist.gil.age.agg
## lenaggfile Aggfiles/catchdistribution.ldist.gil.len.agg
## fleetnames gil
## stocknames lingimm lingmat
## ;
## [component]
## name aldist.gil
## weight 1
## type catchdistribution
## datafile Data/catchdistribution.aldist.gil.sumofsquares
## function sumofsquares
## aggregationlevel 0
## overconsumption 0
## epsilon 10
## areaaggfile Aggfiles/catchdistribution.aldist.gil.area.agg
## ageaggfile Aggfiles/catchdistribution.aldist.gil.age.agg
## lenaggfile Aggfiles/catchdistribution.aldist.gil.len.agg
## fleetnames gil
## stocknames lingimm lingmat
## ;
## [component]
## name ldist.bmt
## weight 1
## type catchdistribution
## datafile Data/catchdistribution.ldist.bmt.sumofsquares
## function sumofsquares
## aggregationlevel 0
## overconsumption 0
## epsilon 10
## areaaggfile Aggfiles/catchdistribution.ldist.bmt.area.agg
## ageaggfile Aggfiles/catchdistribution.ldist.bmt.age.agg
## lenaggfile Aggfiles/catchdistribution.ldist.bmt.len.agg
## fleetnames bmt
## stocknames lingimm lingmat
## ;
## [component]
## name aldist.bmt
## weight 1
## type catchdistribution
## datafile Data/catchdistribution.aldist.bmt.sumofsquares
## function sumofsquares
## aggregationlevel 0
## overconsumption 0
## epsilon 10
## areaaggfile Aggfiles/catchdistribution.aldist.bmt.area.agg
## ageaggfile Aggfiles/catchdistribution.aldist.bmt.age.agg
## lenaggfile Aggfiles/catchdistribution.aldist.bmt.len.agg
## fleetnames bmt
## stocknames lingimm lingmat
## ;
## [component]
## name matp.surv
## weight 1
## type stockdistribution
## datafile Data/stockdistribution.matp.surv.sumofsquares
## function sumofsquares
## overconsumption 0
## epsilon 10
## areaaggfile Aggfiles/stockdistribution.matp.surv.area.agg
## ageaggfile Aggfiles/stockdistribution.matp.surv.age.agg
## lenaggfile Aggfiles/stockdistribution.matp.surv.len.agg
## fleetnames surv
## stocknames lingimm lingmatNote here that Rgadget automatically creates references to necessary data files (‘Data/…’) and
aggregation files (‘Agg/…’) that define the bin structure as defined by data attributes
(see previous section). When write.gadget.file is finally called after we are done adding
all likelihood components, these data and agg files will be written alongside this likelihood
file, and a reference to this likelihood file will also be drawn within the ‘main’ file.
You can also see how individual aggregation files will be printed by e.g.:
## ; Generated by Rgadget 0.5
## age3 3
## age4 4
## age5 5
## age6 6
## age7 7
## age8 8
## age9 9
## age10 10
## age11 11 12 13 14 15which gives you the age aggregation for the second likelihood component.
7.3.1 Setting up survey indices
Incorporating survey index components is very similar except that 1) the fact that the survey
index is length-based is determined by the length attribute of the data frame, which sets the
argument si_type to a value of lengths, and 2) a catchability function is also specified
under the argument 'fittype'. In addition, the argument biomass has a default setting of 0,
signifying a numbers-based index (rather than a biomass-based index, which has a value of 1).
Other options for si_type can be read about in the Gadget User Guide, and ages, fleets, acoustic, and effort.
The catchability function defines the type of linear regression to be used to calculate
the likelihood score. Options include a linear fit on the orignal or log scale (linearfit
or loglinearfit), linear fit with a fixed slope on the original or log scale (fixedslopelinearfit
or fixedslopeloglinearfit), linear fit with a fixed intercept on the original or log scale
(fixedinterceptlinearfit or fixedinterceptlinearfit), or a linear/loglinear function with
both the slope and intercept fixed (fixedlinearfit or fixedloglinearfit). In the first set
of cases (linear or loglinear fits), two parameters would be estimated; in the next two sets of
cases, only a single parameter is estimated (slope or intercept, whichever is not fixed). In
the last set of cases (fixed liner or loglinear fits), no parameters are estimated. Whenever a
parameter is fixed, its value needs to be included as an additional argument to gadget_update.
For example, catchability of the indices of smaller sized fish below are estimated using a
log linear fit with both slopes and intercepts estimated, but catchabilities for indices of
larger sized fish are calculated using log linear fits with fixed slopes. The slopes are
fixed to a value of 1, so the argument slope = 1 is included in the gadget_update call.
Notice that, unlike the distributional likelihood components, a fleet is not specified
for the survey indices, unless si_type is set to fleets, effort, acoustic (rather than length as in our example).
When indices are not length- or age-based, a single catchability is estimated, rather
than the series of catchabilities estimated for each age or length index series.
Each survey index is
matched to stock size observations at a given time and area; therefore, if there are two
length- or age-based survey index series with the same time and area, they can each be
incorporated as separate likelihood components as long as they have different names.
lik <-
lik %>%
gadget_update("surveyindices",
name = paste0("si.", names(slices)[1]),
weight = 1,
data = SI1,
fittype = 'loglinearfit',
stocknames = c("lingimm","lingmat")) %>%
gadget_update("surveyindices",
name = paste0("si.", names(slices)[2]),
weight = 1,
data = SI2,
fittype = 'loglinearfit',
stocknames = c("lingimm","lingmat")) %>%
gadget_update("surveyindices",
name = paste0("si.", names(slices)[3]),
weight = 1,
data = SI3,
fittype = 'fixedslopeloglinearfit',
slope=1,
stocknames = c("lingimm","lingmat")) %>%
gadget_update("surveyindices",
name = paste0("si.", names(slices)[4]),
weight = 1,
data = SI4,
fittype = 'fixedslopeloglinearfit',
slope=1,
stocknames = c("lingimm","lingmat")) %>%
gadget_update("surveyindices",
name = paste0("si.", names(slices)[5]),
weight = 1,
data = SI5,
fittype = 'fixedslopeloglinearfit',
slope=1,
stocknames = c("lingimm","lingmat")) %>%
gadget_update("surveyindices",
name = paste0("si.", names(slices)[6]),
weight = 1,
data = SI6,
fittype = 'fixedslopeloglinearfit',
slope=1,
stocknames = c("lingimm","lingmat")) %>%
gadget_update("surveyindices",
name = paste0("si.", names(slices)[7]),
weight = 1,
data = SI7,
fittype = 'fixedslopeloglinearfit',
slope=1,
stocknames = c("lingimm","lingmat"))
lik Finally, there are two components to the likelihood that do not incorporate data but are instead used to ensure that the optimisation search algorithm remains within reasonable ranges of the defined model. The first component provides penalties to for exceeding parameter bounds as set by the user in the input parameter file. In this example, the weight is set to 0.5, but see the troubleshooting page for cases in which it may be wise to set this weight higher. The data frame provided to this likelihood component specifies the power and parameter weights supplied if the parameter value exceeds its upper and lower bounds. If the likelihood of a parameter exceeds either the upper or lower bound, the distance between the bound and the parameter value is squared and multiplied by the parameter weights 10 000; then the sum of these scores across all parameters is multiplied by the 0.5 weighting before being summed along with the other likelihood components to form the total.
7.3.2 Penalty functions
Understocking introduces a penalty when there are insufficent prey to met the requirements of the predators. For example, if landings of the fleets exceeds available biomass, then the penalty is applied. The understocking penalty likelihood is then defined as the sum of the number of prey that are ‘missing’, raised to a power set by default to 2, and multiplied by the likelihood weight of 100 as indicated below.
lik <-
lik %>%
gadget_update("penalty",
name = "bounds",
weight = "0.5",
data = data.frame(
switch = c("default"),
power = c(2),
upperW=10000,
lowerW=10000,
stringsAsFactors = FALSE)) %>%
gadget_update("understocking",
name = "understocking",
weight = "100")
lik %>%
write.gadget.file(gd)Notice that when the likelihood file is written, so are all the supporting aggregation files under the ‘Aggfiles’ folder.
7.4 Fitting a Gadget model to data
Now that all data and likelihood components are incorporated, it is possible to run gadget_optimise to run a fitting procedure. Like any other optimisation routine, what is still needed are 1) starting values for the parameters, and 2) optimisation routine settings.
7.4.1 Create starting values
If we start here with the same simple gadget_evaluate simulation as in day 2 of the
ling model, we can see that a file called ‘params.out’ is automatically generated
(same timestamp as the simple_log). However, if you open this file, is shows that
each parameter was given a value of 1 with bounds set to {-9999, 9999} and no
optimisation (0). Therefore, this simulation was run with very unrealistic parameters.
Obviously this is not a helpful run in itself, but it is at least useful for
conveniently generating an initial parameter file with the correct Gadget
structure containing all the parameters specified throughout the Gadget model files.
## [1] "/home/runner/work/gadget-course/gadget-course/ling_model/01-base"read.gadget.parameters(paste0(gd,'/params.out')) %>%
DT::datatable(.) #this last line not necessary - helps with printing to web pageNow that the structure is set, it is much easier to change the bounds and starting
values to more realistic ones using init_guess. This function uses the grepl
function internally to match names, so that large chunks of parameters with similar
names can have their bounds similarly changed.
lw_pars <- c(0.00000228, 3.20) #same values as in day 2
## update the input parameters with sane initial guesses
read.gadget.parameters(sprintf('%s/params.out',gd)) %>%
init_guess('rec.[0-9]|init.[0-9]',1,0.001,1000,1) %>%
init_guess('recl',12,4,20,1) %>%
init_guess('rec.sd',5, 4, 20,1) %>%
init_guess('Linf',160, 100, 200,1) %>%
init_guess('k$',90, 40, 100,1) %>%
init_guess('bbin',6, 1e-08, 100, 1) %>%
init_guess('alpha', 0.5, 0.01, 3, 1) %>%
init_guess('l50',50,10,100,1) %>%
init_guess('walpha',lw_pars[1], 1e-10, 1,0) %>%
init_guess('wbeta',lw_pars[2], 2, 4,0) %>%
init_guess('M$',0.15,0.001,1,0) %>%
init_guess('rec.scalar',400,1,500,1) %>%
init_guess('init.scalar',200,1,300,1) %>%
init_guess('mat2',60,0.75*60,1.25*60,1) %>%
init_guess('mat1',70, 10, 200, 1) %>%
init_guess('init.F',0.4,0.1,1,1) %>%
write.gadget.parameters(.,file=sprintf('%s/params.in',gd))
read.gadget.parameters(sprintf('%s/params.in',gd)) %>%
DT::datatable(.) #this last line not necessary - helps with printing to web pageNow is a good point to scan the resulting ‘params.in’ file to make sure that a parameter was not forgotten and left with default values and bounds.
7.4.1.1 Exercise
Suppose that age sampling was done so that the same sampling effort was spread across all ages equally (roughly 30 fish per length range to attain roughly 30 age samples per age). Change the likelihood component function for age-length data to the appropriate function.
Change the survey indices to be biomass indices using
gadget_update.Use
init_guessto change the bounds of only one set of selectivity parameters.
7.5 Set optimisation routine
To run an optimisation via gadget_optimize is simple, the user provides an input parameter file with starting values
(below as params.in = 'params.in'), and providing a file name to which final parameter
values should be written (below as params.out = 'params.init').
Now that reasonable bounds and starting values have been set for an
optimisation run, default settings can be used to run a short and simple
Gadget optimisation. If you open the params.init file, comments can be found
at the top that detail the computer and timing of the run (as in a simulation run),
as well as optimisation information (something like ‘Hooke & Jeeves algorithm ran
for 1039 function evaluations’), the likelihood value at the end ‘1e+10’ and a
reason for stopping (‘because the maximum number of function evaluations was reached’).
You can also see from the timestamps above that this run took roughly 30 seconds,
depending on the computer being used.
Obviously, the default settings for optimisation (1000 function evaluations using the Hooke and Jeeves algorithm), are insufficient to find a reasonable optimum. Gadget can also take quite a while to optimise a model (~ 6 hours for ling on a very fast computer). Therefore, it is best to plan ahead of time on which computer and when a model will be optimised, as well as which optimisation methods will be used.
To change from the default settings, an opimisation file needs to be provided
to gadget_optimize via the control argument. This is the file we provide for
demonstration: it shows that we have implemented 3 consecutive optimisation
routines. The first begins with simulated annealing (and parameter settings
needed for it as well as a seed), followed by a Hooke and Jeeves algorithm
that begins where simulated annealing leaves off, and finally a BFGS algorithm.
The three routines are listed in this manner to consecutively to transition from
a broader global search (simulated annealing) to one that provides faster
(Hooke and Jeeves) and more precise (BFGS) results, in an attempt to make the
search more efficient. These three are the only algorithms currently implemented,
but others are in a development phase. Also note that a seed is set in the
beginning algorithm: it is good practice to both use random starting values
as well as a set seed to check for possible optimisation problems. More
information on parameters specific to each algorithm can be found in the Gadget User Guide.
Each algorithm also has a low maximum number of iterations set in the optimisation file below, which is clearly not enough to be realistic: realistic values used for ling are given as notes within the optinfofile and are not read below. However, the each model presents new challenges to the search algorithm, so in some complex cases it may be necessary to rely mostly on simulating annealing, whereas in other more well-defined cases it may be possible to rely mostly on the faster algorithms. At this point in development, speeding Gadget runs is mostly done by using computers with multiple cores and faster processors.
## ; Generated by Rgadget 0.5
## [simann]
## simanniter 200 ; number of simulated annealing iterations, normally set to 1000000 for ling
## simanneps 0.001 ; minimum epsilon, simann halt criteria
## t 30000000 ; simulated annealing initial temperature
## rt 0.85 ; temperature reduction factor
## nt 2 ; number of loops before temperature adjusted
## ns 5 ; number of loops before step length adjusted
## vm 1 ; initial value for the maximum step length
## cstep 2 ; step length adjustment factor
## lratio 0.3 ; lower limit for ratio when adjusting step length
## uratio 0.7 ; upper limit for ratio when adjusting step length
## check 4 ; number of temperature loops to check
## seed 5908
## [hooke]
## hookeiter 100 ; number of hooke & jeeves iterations, normally set to 40000 for ling
## hookeeps 1e-04 ; minimum epsilon, hooke & jeeves halt criteria
## rho 0.5 ; value for the resizing multiplier
## lambda 0 ; initial value for the step length
## [bfgs]
## bfgsiter 100 ; number of bfgs iterations, normally set to 10000 for ling
## bfgseps 0.01 ; minimum epsilon, bfgs halt criteria
## sigma 0.01 ; armijo convergence criteria
## beta 0.3 ; armijo adjustment factor
## Here, we have implemented a fitting procedure that begins where the last default optimisation values left off (in the ‘params.init’ file). The ‘params.opt’ file will therefore be the result of a longer and more well-defined search as described by the ‘optinfofile’.
timestamp()
gadget_optimize(gd,params.in = 'params.in', params.out = 'params.init', control = optinfo)
timestamp()7.5.0.1 Exercise
- Try changing the parameter starting values to the params.forsim file within the ‘data_provided’ folder. Does the optimisation finish any quicker?
7.6 Using the iterative reweighting function to fit a Gadget statistical model
The total objective function used the modeling process combines equations to using the following formula:
\[\begin{equation}\label{eq:loglik} l^{T} = \sum_g w_{gf}^{SI} l_{g,S}^{SI} + \sum_{f\in \{S,T,G,L\}} \left( w_{f}^{LD} l_{f}^{LD} + w_{f}^{AL} l_{f}^{AL}\right) + w^{M}l^{M} \end{equation}\] where \(f=S,T,G\) or \(L\) denotes the spring survey, trawl, gillnet and longline fleets respectively and \(w\)’s are the weights assigned to each likelihood components.
The weights, \(w_i\), are necessary for several reasons. First of all it is used to to prevent some components from dominating the likelihood function. When one data source dominates, the model fits that one exactly and ignores information from the other data sources. Another would be to reduce the effect of low quality data. It can be used as an a priori estimates of the variance in each subset of the data.
Assigning likelihood weights is not a trivial matter; it has in the past
been the most time-consuming part of developing a Gadget model. Historicall this was
been done using some form of ‘expert judgement’. General heuristics
have recently been developed to estimated these weights
objectively. Here the iterative re–weighting heuristic introduced by
Stefánsson (2003), and subsequently implemented in
Taylor et al. (2007), is used. Rgadget implements this heuristing using the gadget.iterative function.
The general idea behind the iterative re-weighting is to assign the inverse variance of the fitted residuals as component weights. This pattern suggests that the more variable the residuals are from a particular data source, the less weight it should receive. The variances, and hence the final weights, are calculated according the following algorithm:
- Calculate the initial sums of squares (SS) given the initial parameterization for all likelihood components. Assign the inverse SS as the initial weight for all likelihood components, resulting in a total initial score of 1 for each component.
- For each likelihood component, do an optimization run with the initial weighted SS for that component set to 10 000. This run represents a model fit where essentially only that component contributes to model fitting, and therefore that component receives the best fit achievable. Then estimate the residual variance using the resulting SS of that component divided by the degrees of freedom (\(df^*\)), i.e. \(\hat{\sigma}^2 = \frac{SS}{df^*}\).
- After the optimization of each component separately, set the final weight for each component to be the inverse of the estimated variance from the step above (weight \(=1/\hat{\sigma}^2\)).
The number of non-zero data-points (\(df^{*}\)) is used as a proxy for the degrees of freedom. While this may be a satisfactory proxy for larger data sets, it could be a gross overestimate of the degrees of freedom for smaller data sets. In particular, if the survey indices are weighed on their own while the annual recruitment is estimated, they could be over-fitted. In general, problem such as these can be solved with component grouping. Component grouping is achieved in step 2: likelihood components that should behave similarly, such as survey indices representing similar age ranges, are weighted and optimized together.
The gadget.iterative function implements the iterative reweighting heuristic and is invoked in the following manner:
## In its current version, gadget.iterative needs to be run from within the
## directory that contains the Gadget model
old <- getwd()
file.copy(sprintf('%s/optinfofile','data_provided'),gd)## [1] TRUEsetwd(gd)
## run gadget iterative
## WARNING: Each time gadget.iterative runs with the given optinfofile,
## it takes 11 mins to run on a reasonably fast computer with 2 cores.
timestamp() ## ##------ Wed Dec 9 13:14:29 2020 ------##run <- gadget.iterative() # This works for Linux or Mac, but Windows throws an error due to incompatability in the parallel package
#run <- gadget.iterative(run.serial = TRUE) #This will work, but will take several times as long to run. For demonstration purposes, it is highly recommended to reduce the number of iterations in the optinfofile to a very small number for all algorithms.
timestamp()## ##------ Wed Dec 9 13:18:28 2020 ------##This will start an iterative run that will estimate the weights for all likelihood
components, and run a final optimisation run with the resulting likelihood weights.
Penalising likelihood components, such as boundlikelihood and understocking, are
left as is. As the iterative reweighting requires several optimisation runs,
gadget.iterative tries to spread these runs across the available cores on your
computer. In the case of the number of cores lower than the number of runs, the excess
runs will wait until a core becomes available. The resulting parameter estimates are
then stored in a folder called WGTS in your model directory, where the file
params.final contains the final parameter estimate.
When running gadget.iterative with standard setting you assume that all
data sets have enough data to allow all parameters to be estimated without
overfitting the data. It is not always the case that this is appropriate.
For instance survey indices have in general only one data point per year,
step and size group, and when estimating annual recruitment this usually
leads overfitting of that particular component when heavily emphasized.
Similar problem can arise when only one year, or a few disjoint years,
worth of compositional data is supplied to the likelihood function. To
account for this issue the user can group similar likelihood components
together using the grouping argument in the gadget.iterative function.
When estimating annual recruitment, for example, this ensures that at least
two data points are available to estimate each of the recruitment parameters.
In the case of Ling, the survey indices were split into two groups, sizes 20
to 72 cm and 72 to 160 cm, and the compositional data from the commercial
trawl and gillnet fleets were grouped due to a low number of data points.
Note that when rerunning gadget.reiterative, it is best for file management
purposes to delete the old ‘WGTS’ folder before reruinning gadget.iterative,
for example by running unlink("WGTS", recursive=TRUE).
Alternatively, if both sets of results should be kept, then the ‘WGTS’ folder
should be renamed by changing the default argument wgts = 'WGTS'. This is
especially important when visualizing model results in the next step using
gadget.fit.
run <- gadget.iterative(grouping = list(sind1=c('si.len20','si.len52','si.len60'),
sind2=c('si.len72','si.len80','si.len92',
'si.len100'),
comm=c('ldist.gil','ldist.bmt',
'aldist.gil','aldist.bmt')),
wgts = 'WGTS2') # if working on Windows, can run with argument run.serial = TRUE (see above)Note that if a likelihood component is not present in the defined grouping list it is assumed that the component is treated individually.
If the final run has crashed it is convenient to be able to pick up the “thread”
where the run crashed and resume the final optimisation. The resume.final
switch allows for this and essentially only runs the last optimisation, thereby
assuming that the preceding steps have been completed:
run <- gadget.iterative(resume.final = TRUE,
wgts = 'WGTS') # if working on Windows, can run with argument run.serial = TRUE (see above)Related to resume.final there are the run.final and run.serial arguments
that instruct the function to whether to run the final optimisation from the
beginning and whether all optimisations should be run on a single core respectively.
Note for Windows users: the user needs to explicitly define a cluster for gadget.iterative to run in parallel, see here for ways around this problem.
In post-hoc analyses of the effect of certain data sources on model fitting,
differential treatment of data is often investigated. For example, the effect
of a certain dataset can be analysed by omitting it from the estimation or changing
its grouping. gadget.iterative allows you to have multiple WGTS folders in the
same model directory by setting the wgts argument. In addition the user can
explicitly define (or remove) which component are to be used in the optimisation
using a combination of the comp and inverse arguments:
## only want to fit to ldist.gil, all others discarded
run <- gadget.iterative(comp = 'ldist.gil',
wgts = 'WGTS') # if working on Windows, can run with argument run.serial = TRUE (see above)
## remove ldist.gil, all others kept
run <- gadget.iterative(comp = 'ldist.gil',
inverse = TRUE,
wgts = 'WGTS') # if working on Windows, can run with argument run.serial = TRUE (see above)7.7 Visualize Gadget statistical model fit
To obtain information on the model fit and properties of the model, one can
use the gadget.fit function to query the model and return conveniently
structured output. Notice that there is a default argument in gadget.fit
that matches gadget.reiterative: the wgts = 'WGTS' argument. This means that
by default gadget.fit will load the reiterative results stored under ‘WGTS’,
but this can be changed. Here we load results from the first run of
gadget.iterative where no grouping was implemented.
setwd(gd) # Make sure we are in gd first, or put gd as an argument to gadget.fit
fit <- gadget.fit()## [1] "Reading input data"
## [1] "Running Gadget"
## [1] "Reading output files"
## [1] "Gathering results"
## [1] "Merging input and output"theme_set(theme_light()) ## set the plot theme (optional)
library(patchwork) ## optional packages
scale_fill_crayola <- function(n = 100, ...) {
# taken from RColorBrewer::brewer.pal(12, "Paired")
pal <- c("#A6CEE3", "#1F78B4", "#B2DF8A", "#33A02C",
"#FB9A99", "#E31A1C", "#FDBF6F", "#FF7F00",
"#CAB2D6", "#6A3D9A", "#FFFF99", "#B15928")
pal <- rep(pal, n)
ggplot2::scale_fill_manual(values = pal, ...)
}The fit object is essentially a list of data.frames that contain the likelihood data merged with the model output.
## [1] "sidat" "resTable" "nesTable"
## [4] "suitability" "stock.recruitment" "res.by.year"
## [7] "stomachcontent" "likelihoodsummary" "catchdist.fleets"
## [10] "stockdist" "SS" "stock.full"
## [13] "stock.std" "stock.prey" "fleet.info"
## [16] "predator.prey" "params" "catchstatistics"and one can access those data.frames simply by calling their name:
For further information on what the relevant data.frames contain refer to the help page for gadget.fit.
In addition a plot routine for the fit object is implement in Rgadget. The input to the plot function is simply the gadget.fit object, the data set one wants to plot and the type. The default plot is a survey index plot:
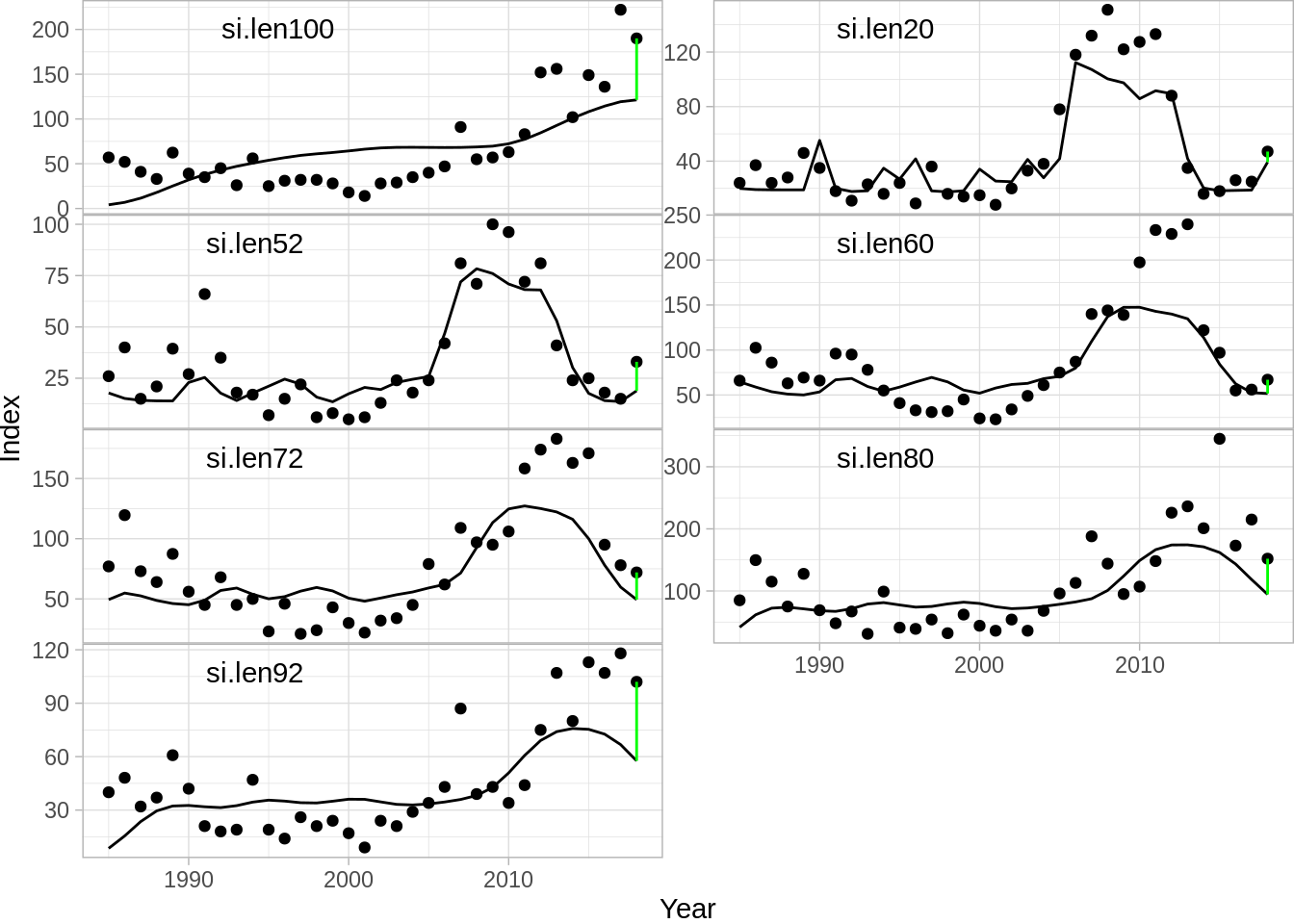
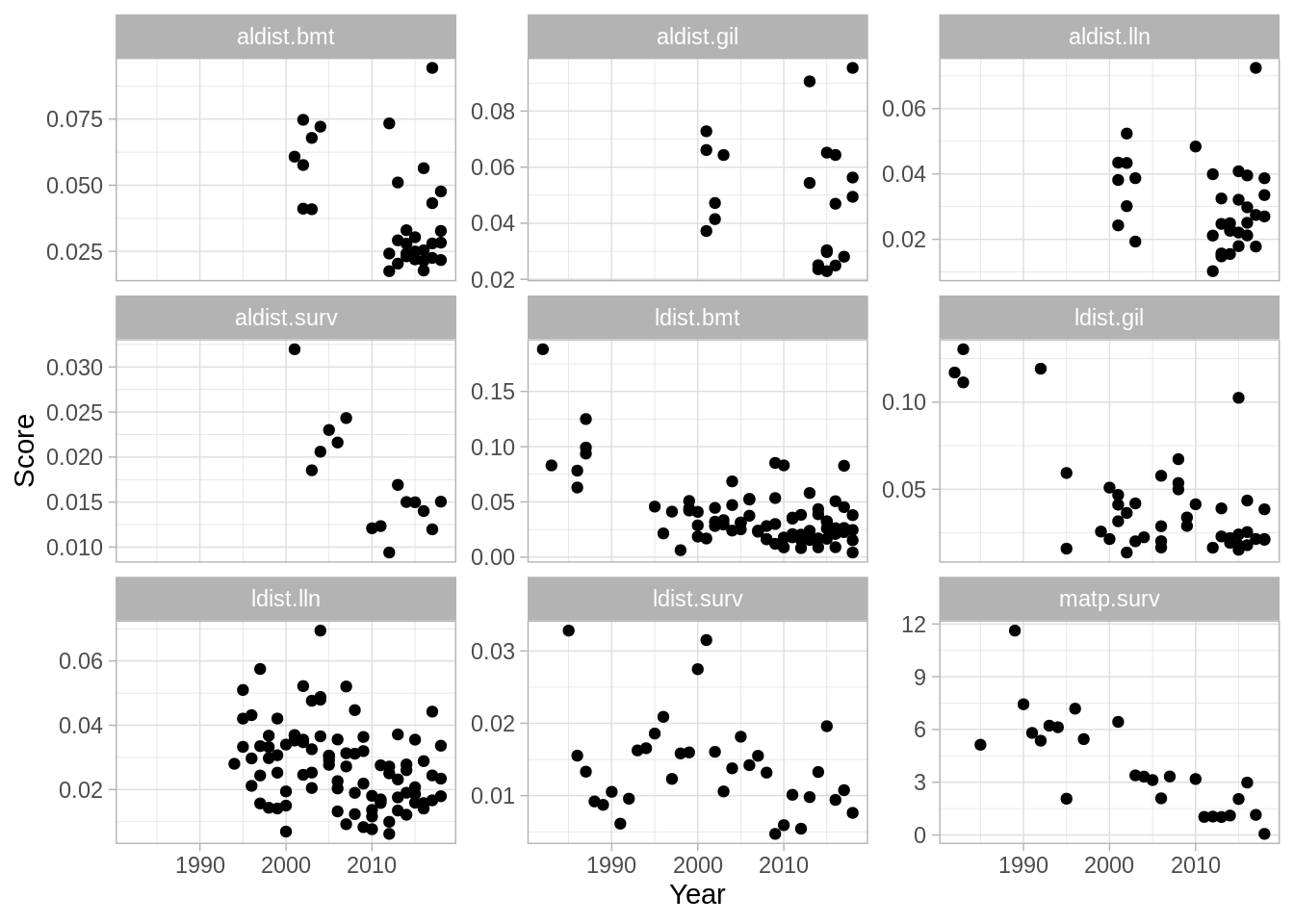
To produce a likelihood summary:
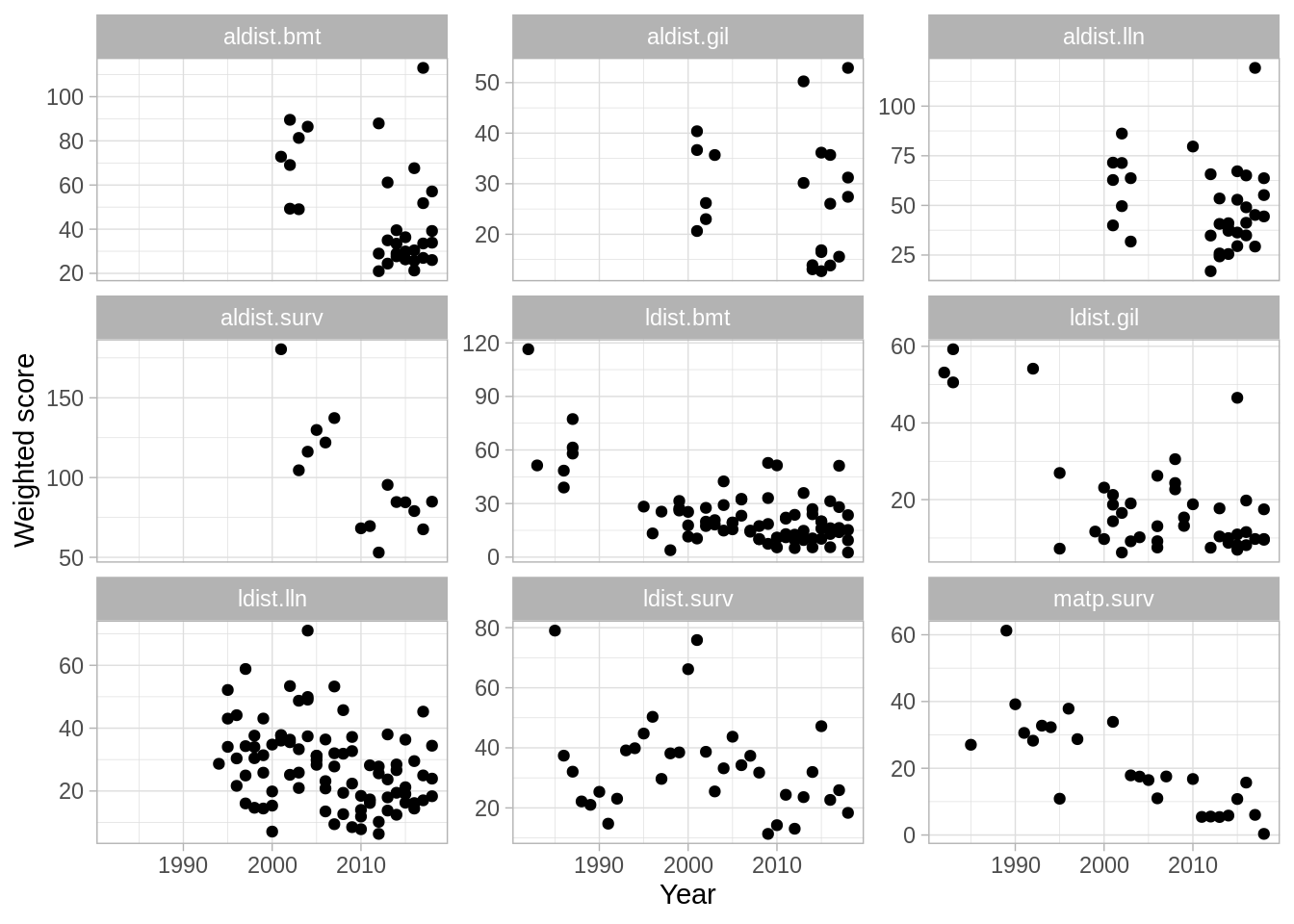
A weighted summary plot:
and a pie chart of likelihood components:
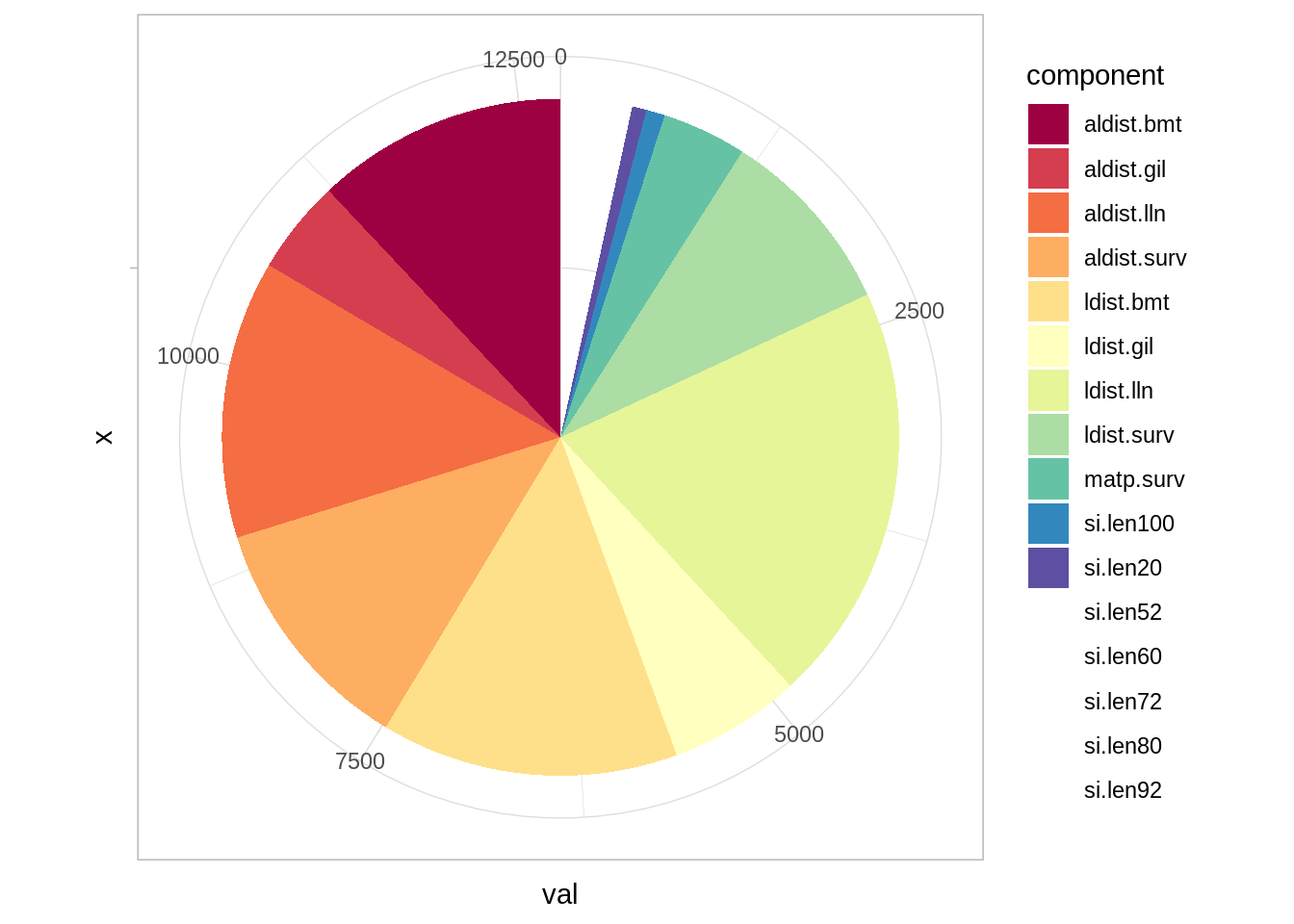
To plot the fit to catch proportions (either length or age) you simply do:
## [1] "aldist.bmt" "aldist.gil" "aldist.lln" "aldist.surv" "ldist.bmt"
## [6] "ldist.gil" "ldist.lln" "ldist.surv"and then plot them one by one:
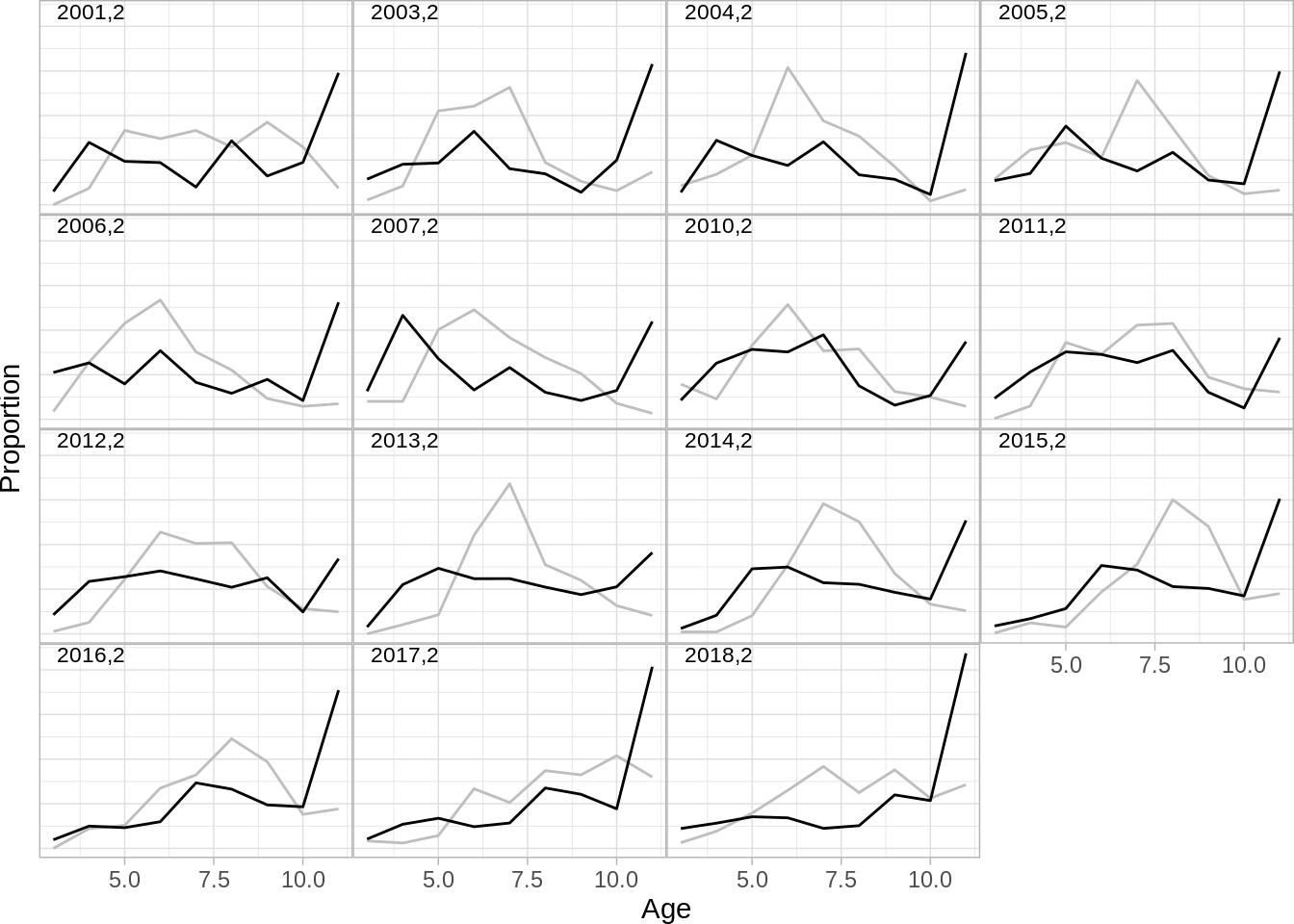
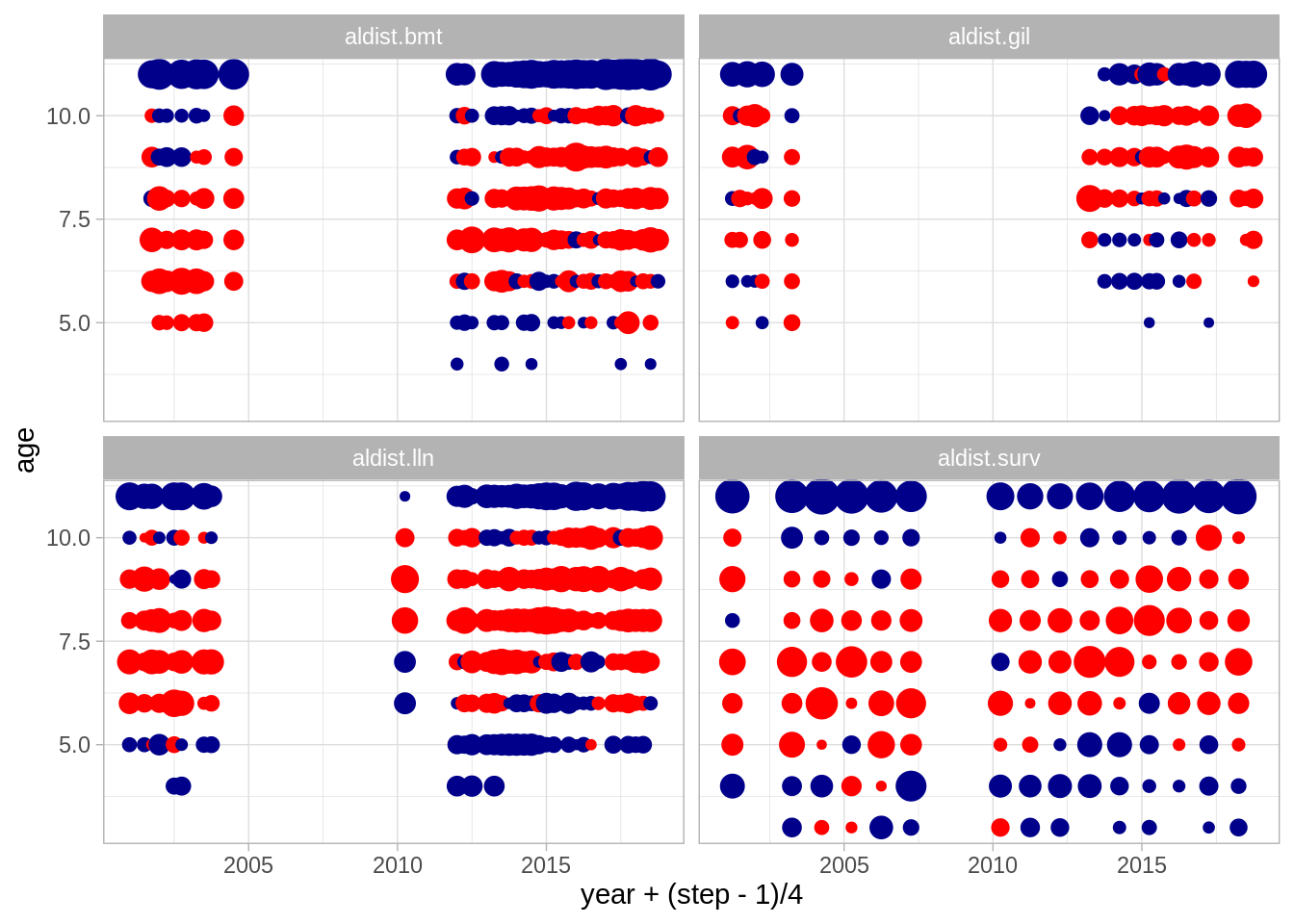
One can also produce bubble plots
## [1] "ldist" "aldist"Age bubbles
Length bubbles
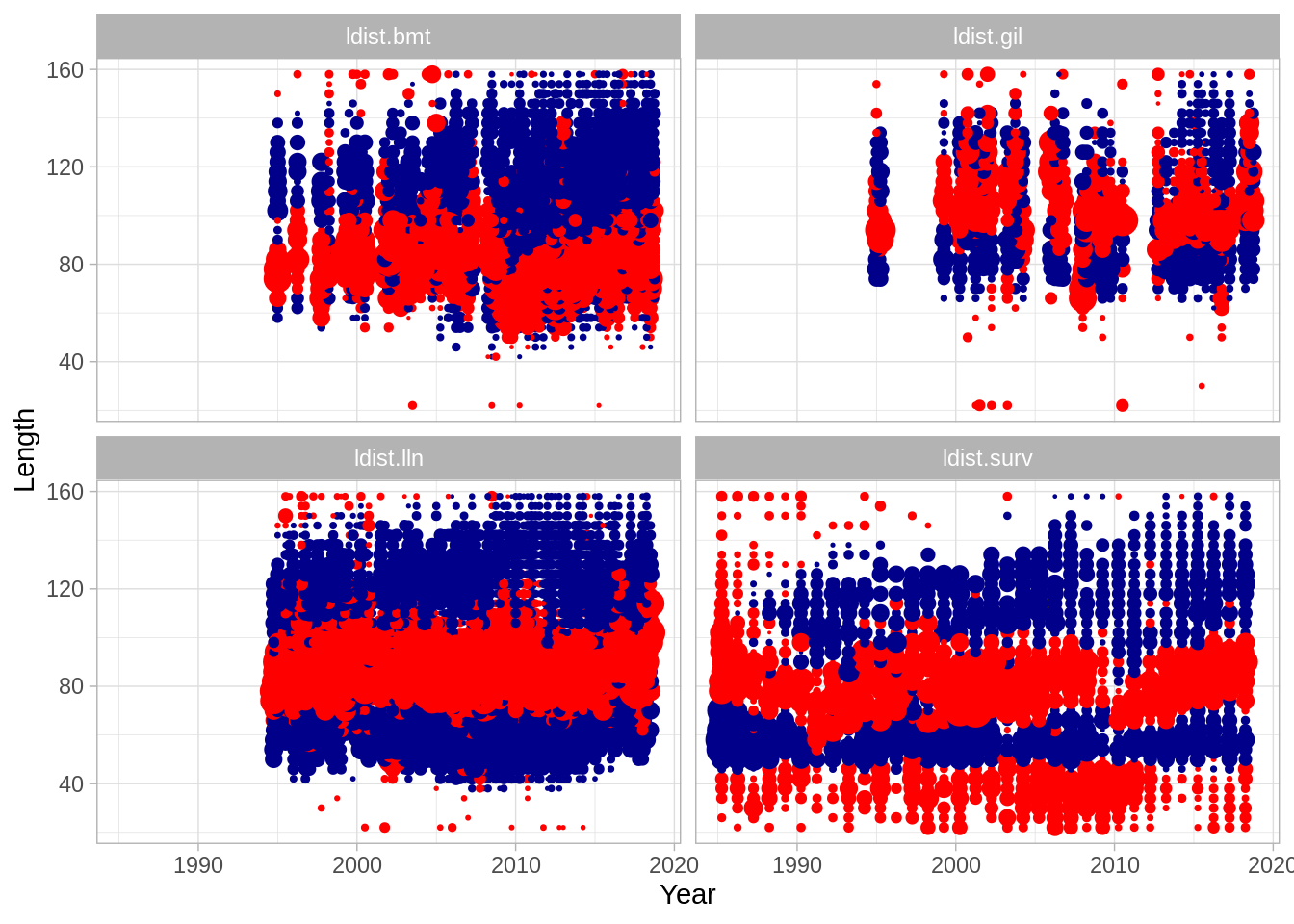
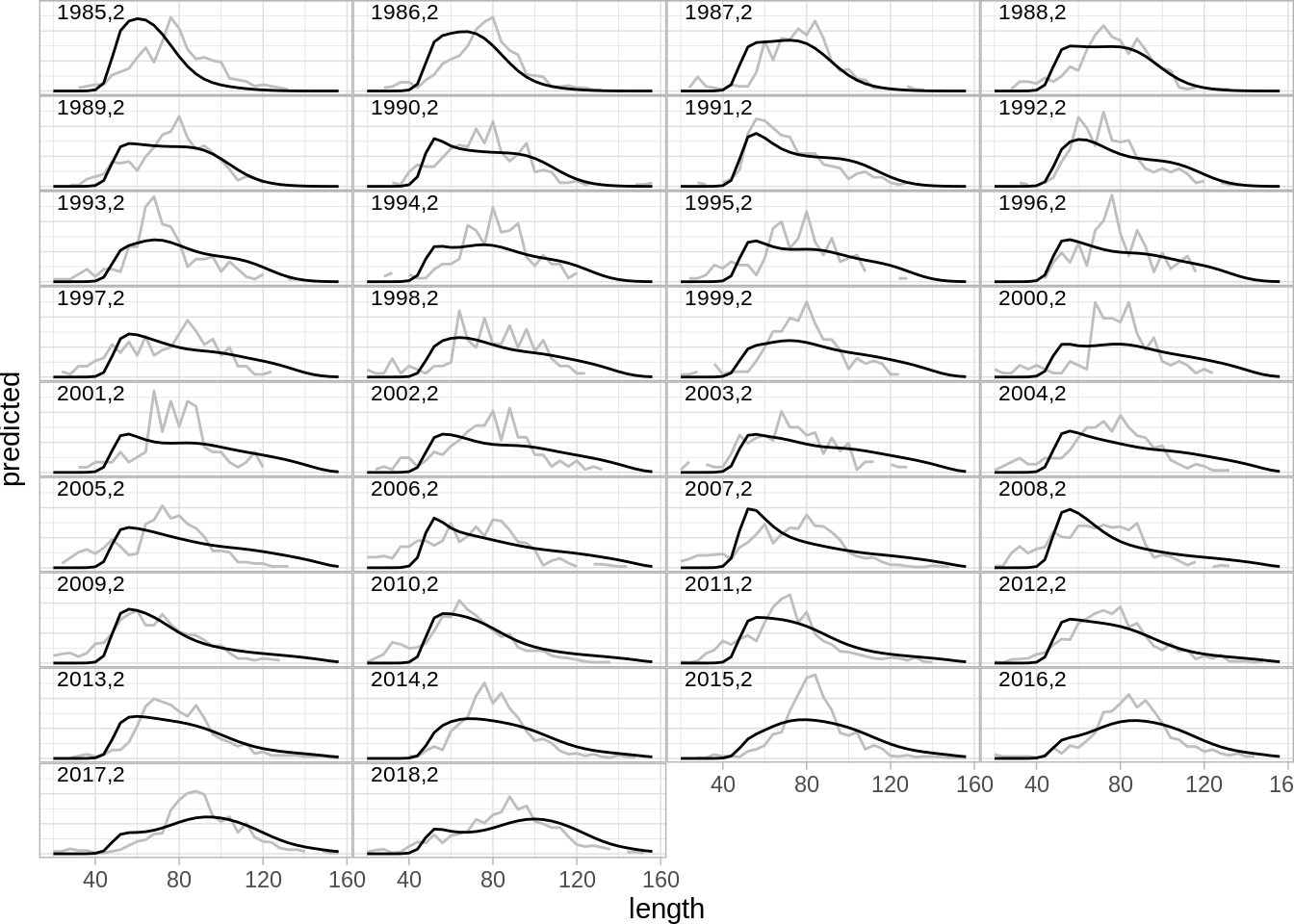
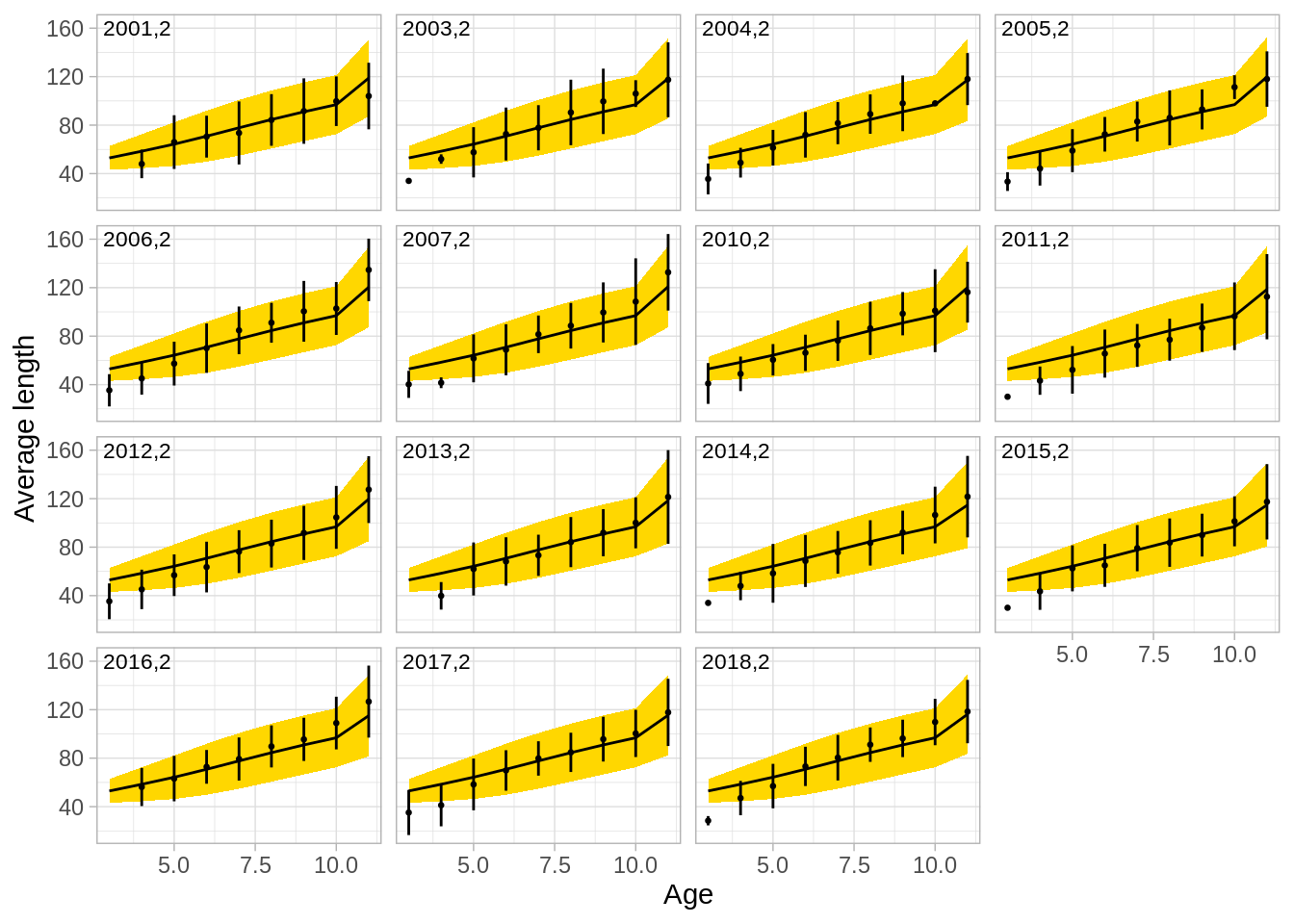
One can also illustrate the fit to growth in the model:
## [1] "aldist.bmt" "aldist.gil" "aldist.lln" "aldist.surv"Illstrate the fit to the autumn survey
And the fit to maturity data:
## $matp.surv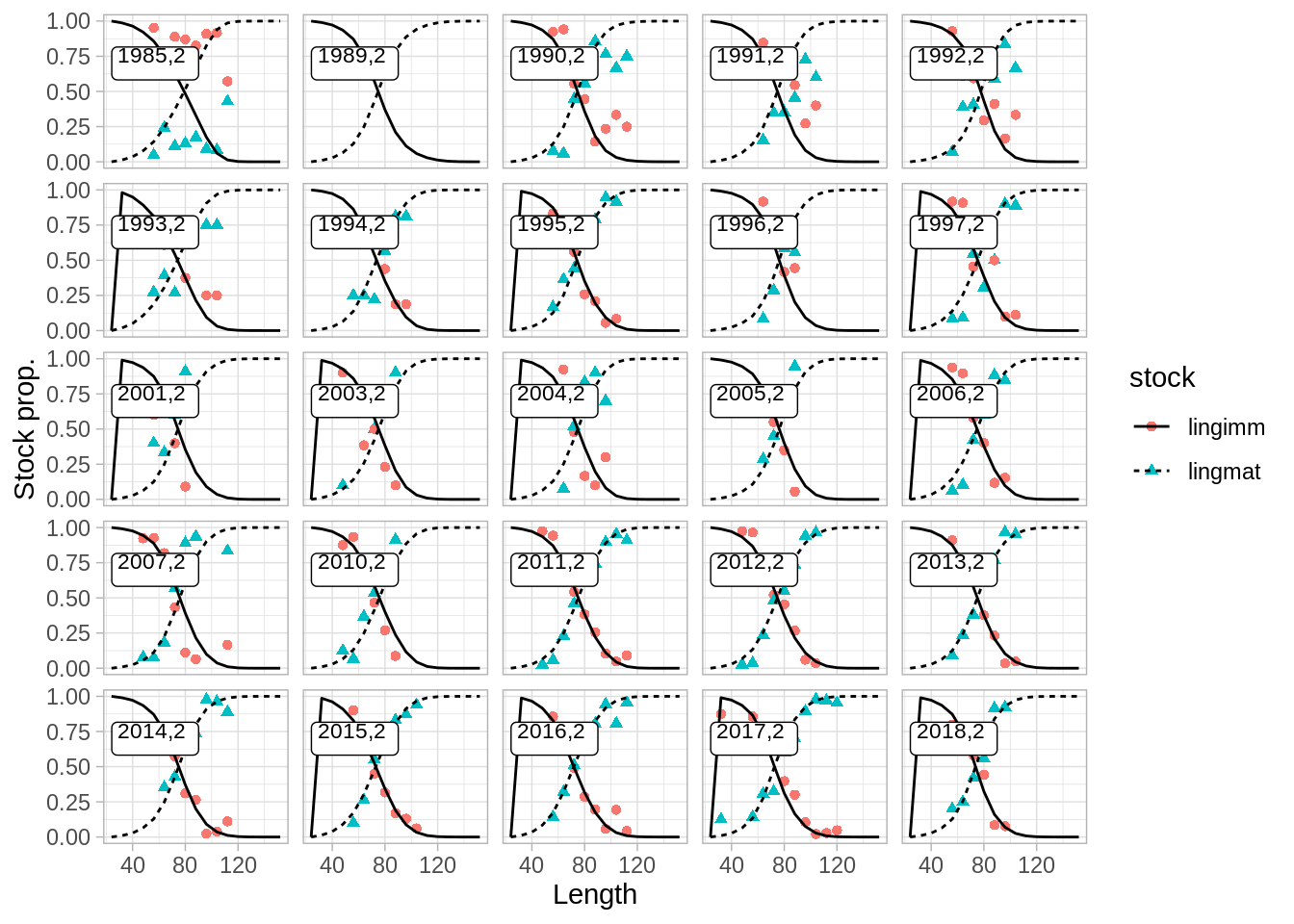
And selection by year and step
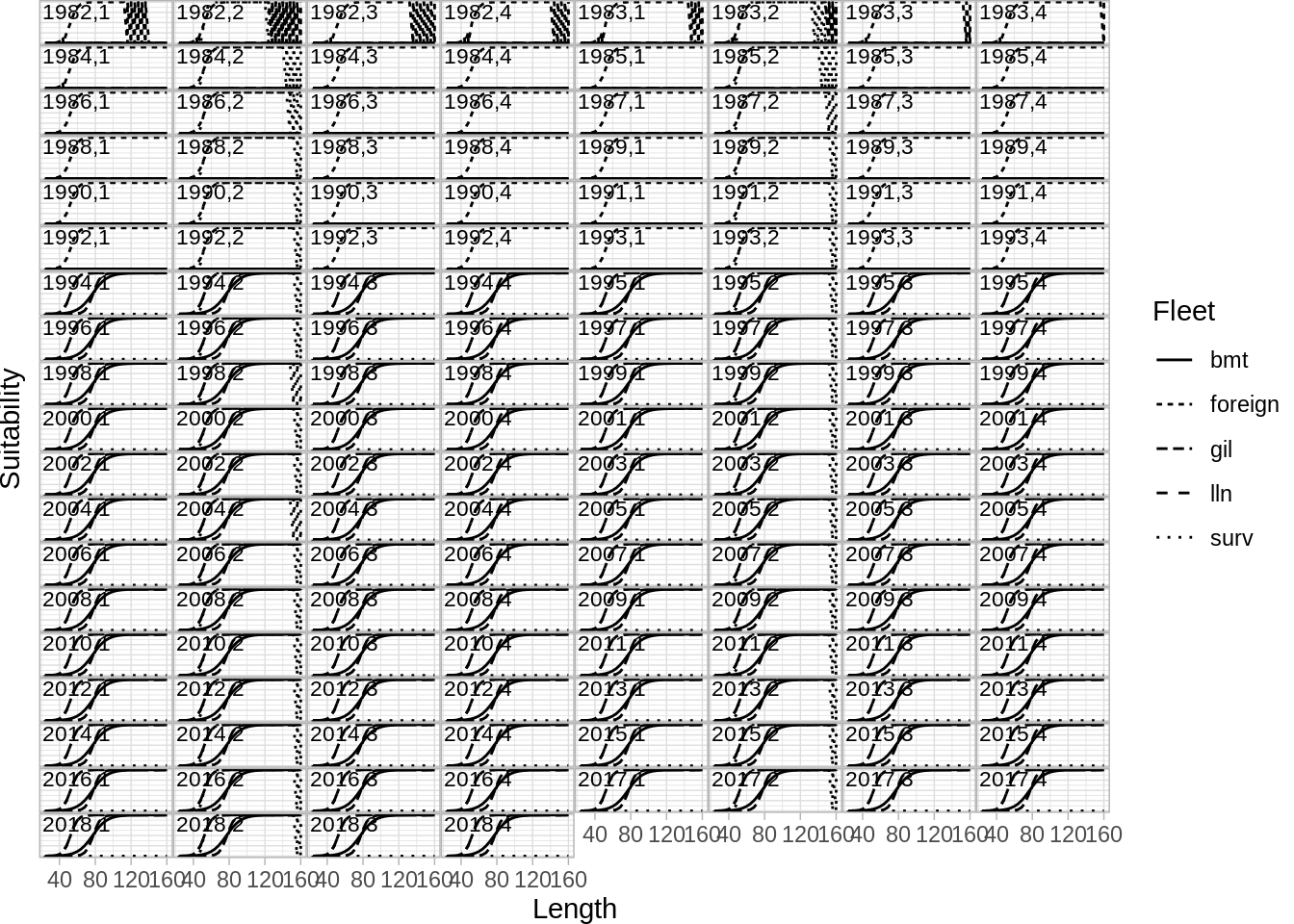
Age age compostion
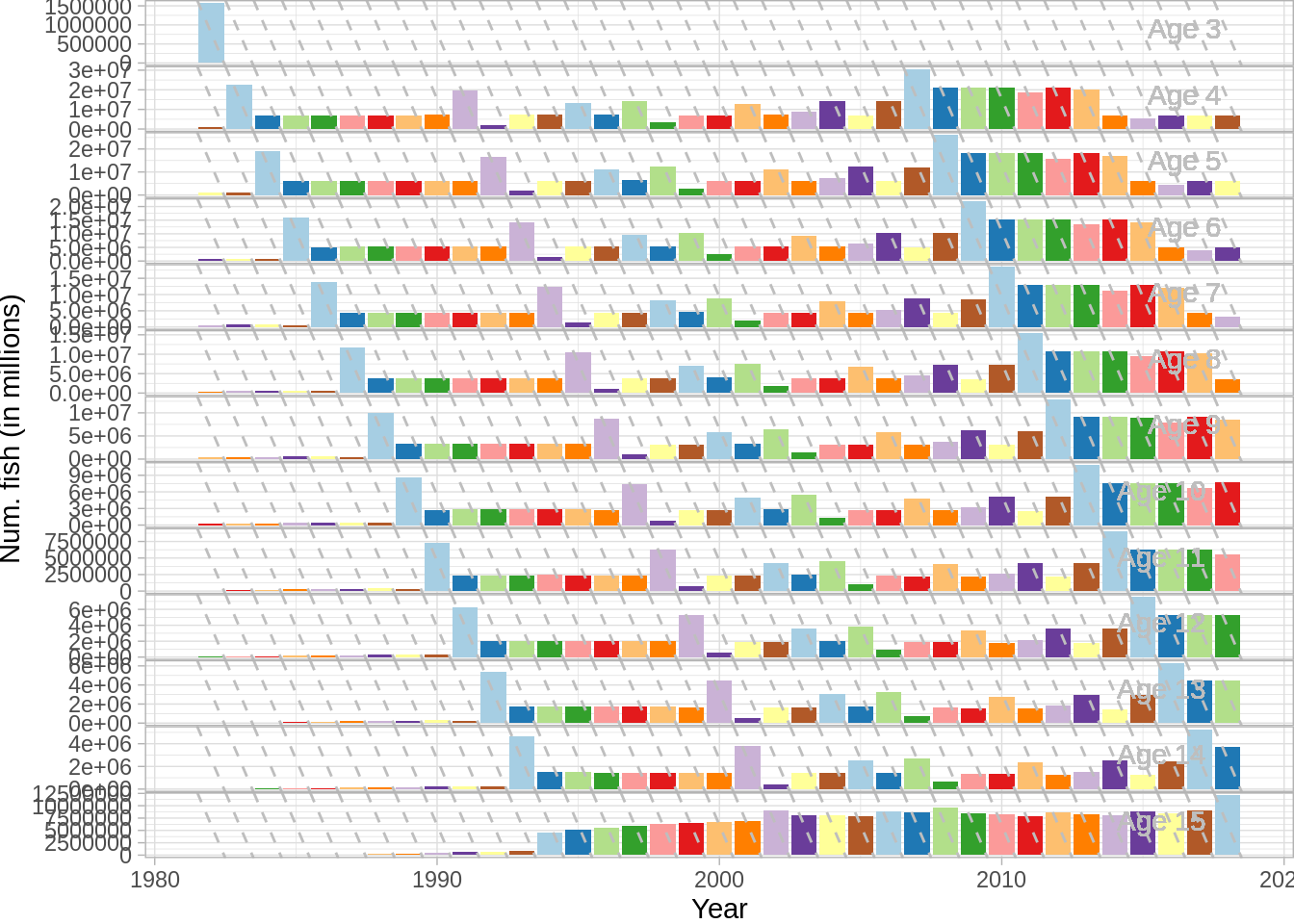
And the standard ICES plots
plot(fit,data='res.by.year',type='total') + theme(legend.position = 'none') +
plot(fit,data='res.by.year',type='F') + theme(legend.position = 'none') +
plot(fit,data = 'res.by.year',type='catch') + theme(legend.position = 'none') +
plot(fit, data='res.by.year',type='rec')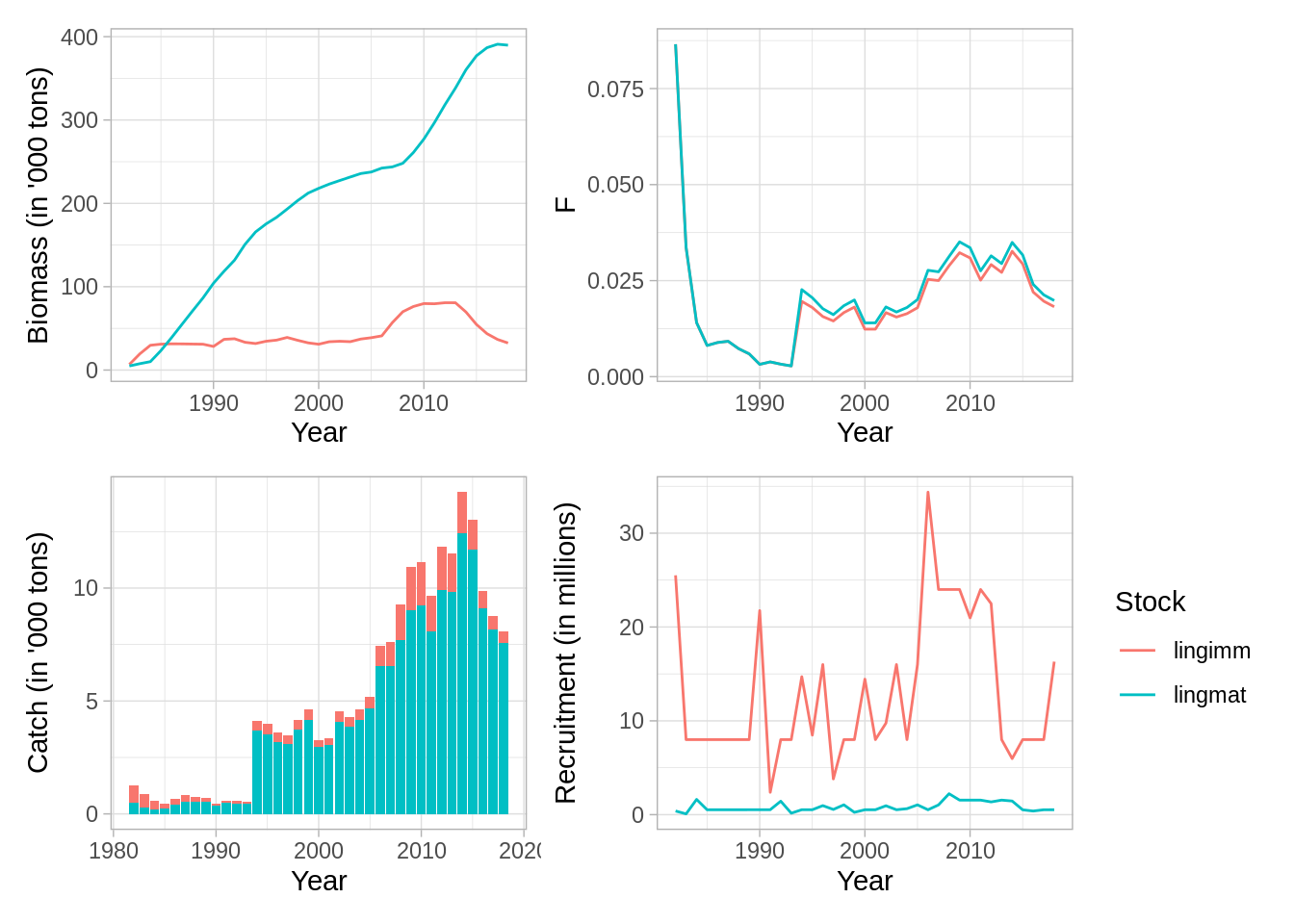
7.7.0.1 Exercise
- Try plotting the catchabilities on the normal scale (exponentiated, not log as given) across ages for each survey. What shape are they when plotted?
- What information is stored under fit$SS?
- Try changing the grouping structure above to one that makes more sense to you. Do model results fit any better?
C References
Stefánsson, Gunnar. 2003. “Issues in Multispecies Models.” Natural Resource Modeling 16 (4): 415–37.
Taylor, L., J. Begley, V. Kupca, and G. Stefansson. 2007. “A simple implementation of the statistical modelling framework Gadget for cod in Icelandic waters.” African Journal of Marine Science 29 (2): 223–45.